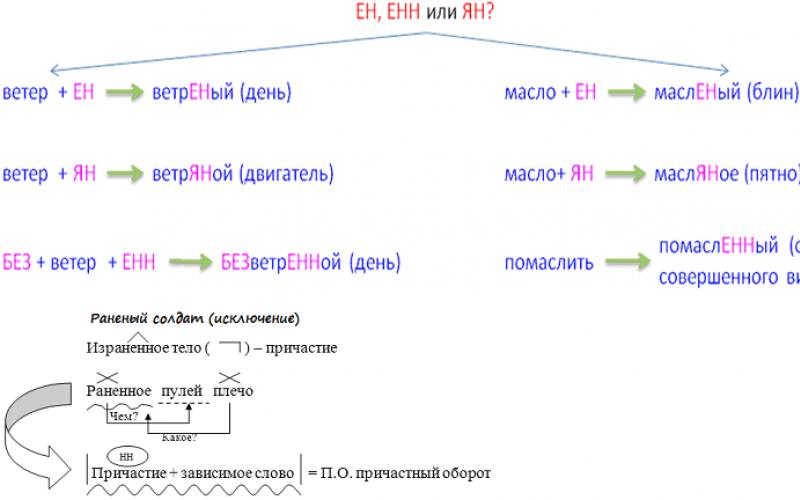
Ряды, построенные по количественному признаку , называются вариационным .
Ряды распределений состоят из вариантов (значений признака) и частот (численности групп). Частоты, выраженные в виде относительных величин (долей, процентов) называются частостями . Сумма всех частот называется объёмом ряда распределения.
По виду ряды распределения делятся на дискретные (построены по прерывным значениям признака) и интервальные (построены на непрерывных значениях признака).
Вариационный ряд представляет собой две колонки (или строки); в одной из которых приводятся отдельные значения варьирующего признака, именуемые вариантами и обозначаемые Х; а в другой – абсолютные числа, показывающие сколько раз (как часто) встречается каждый вариант. Показатели второй колонки называются частотами и условно обозначают через f. Еще раз заметим, что во второй колонке могут использоваться и относительные показатели, характеризующие долю частоты отдельных вариантов в общей сумме частот. Эти относительные показатели именуются частостями и условно обозначают через ω Сумма всех частостей в этом случае равна единице. Однако частоты можно выражать и в процентах, и тогда сумма всех частостей дает 100%.
Если варианты вариационного ряда выражены в виде дискретных величин, то такой вариационный ряд именуют дискретным.
Для непрерывных признаков вариационные ряды строятся как интервальные , то есть значения признака в них выражаются «от… до …». При этом минимальны значения признака в таком интервале именуют нижней границей интервала, а максимальное – верхней границей.
Интервальные вариационные ряды строят и для дискретных признаков, варьирующих в большом диапазоне. Интервальные ряды могут быть с равными и неравными интервалами.
Рассмотрим как определяется величина равных интервалов. Введем следующие обозначения:
i – величина интервала;
- максимальное значение признака у единиц совокупности;
– минимальное значение признака у единиц совокупности;
n – число выделяемых групп.
, если n известно.
Если число выделяемых групп трудно заранее определить, то для расчета оптимальной величины интервала при достаточном объеме совокупности может быть рекомендована формула, предложенная Стерджессом в 1926 году:
n = 1+ 3.322 lg N, где N – число единиц в совокупности.
Величина неравных интервалов определяется в каждом отдельном случае с учетом особенностей объекта изучения.
Статистическим распределением выборки называют перечень вариант и соответствующих им частот (или относительных частот).
Статистическое распределение выборки можно задать в виде таблицы, в первой графе которой располагаются варианты, а во второй - соответствующие этим вариантам частоты ni , или относительные частоты Pi .
Статистическое распределение выборки
Интервальными называются вариационные ряды, в которых значения признаков, положенных в основу их образования, выражены в определенных пределах (интервалах). Частоты в этом случае относятся, не к отдельным значениям признака, а ко всему интервалу.
Интервальные ряды распределения строятся по непрерывным количественным признакам, а также по дискретным признакам, варьирующим в значительных пределах.
Интервальный ряд можно представить статистическим распределением выборки с указанием интервалов и соответствующих им частот. При этом в качестве частоты интервала принимают сумму частот вариант, попавших в этот интервал.
При группировке по количественным непрерывным признакам важное значение имеет определение размера интервала.
Кроме выборочной средней и выборочной дисперсии применяются и другие характеристики вариационного ряда.
Модой называют варианту, которая имеет наибольшую частоту.
Вариационный ряд – ряд, в котором сопоставлены (по степени возрастания или убывания) варианты и соответствующие им частоты
Варианты – отдельные количественные выражения признака. Обозначаются латинской буквой V . Классическое понимание термина "варианта" предполагает, что вариантой называется каждое уникальное значение признака, без учета количества повторов.
Например, в вариационном ряду показателей систолического артериального давления, измеренного у десяти пациентов:
110, 120, 120, 130, 130, 130, 140, 140, 160, 170;
вариантами являются только 6 значений:
110, 120, 130, 140, 160, 170.
Частота – число, показывающее, сколько раз повторяется варианта. Обозначается латинской буквой P . Сумма всех частот (которая, разумеется, равна числу всех исследуемых) обозначается как n .
- В нашем примере частоты будут принимать следующие значения:
- для варианты 110 частота Р = 1 (значение 110 встречается у одного пациента),
- для варианты 120 частота Р = 2 (значение 120 встречается у двух пациентов),
- для варианты 130 частота Р = 3 (значение 130 встречается у трех пациентов),
- для варианты 140 частота Р = 2 (значение 140 встречается у двух пациентов),
- для варианты 160 частота Р = 1 (значение 160 встречается у одного пациента),
- для варианты 170 частота Р = 1 (значение 170 встречается у одного пациента),
Виды вариационных рядов:
- простой - это ряд, в котором каждая варианта встречается только по одному разу (все частоты при этом равны 1);
- взвешенный - ряд, в котором одна или несколько вариант встречаются неоднократно.
Вариационный ряд служит для описания больших массивов чисел, именно в этой форме изначально представляются собранные данные большинства медицинских исследований. Для того, чтобы охарактеризовать вариационный ряд, рассчитываются специальные показатели, в том числе средние величины, показатели вариабельности (так называемой, дисперсии), показатели репрезентативности выборочных данных.
Показатели вариационного ряда
1) Средняя арифметическая - это обобщающий показатель, характеризующий размер изучаемого признака. Средняя арифметическая обозначается как M , представляет собой самый распространенный вид средней. Средняя арифметическая рассчитывается как отношение суммы значений показателей всех единиц наблюдения к числу всех исследуемых. Методика расчета средней арифметической различается для простого и взвешенного вариационного ряда.
Формула для расчета простой средней арифметической:
Формула для расчета взвешенной средней арифметической:
M = Σ(V * P)/ n
2) Мода – еще одна средняя величина вариационного ряда, соответствующая наиболее часто повторяющейся варианте. Или, если выразиться по другому, это варианта, которой соответствует наибольшая частота. Обозначается как Мо . Мода рассчитывается только для взвешенных рядов, так как в простых рядах ни одна из вариант не повторяется и все частоты равны единице.
Например, в вариационном ряду значений частоты сердечных сокращений:
80, 84, 84, 86, 86, 86, 90, 94;
значение моды составляет 86, так как данная варианта встречается 3 раза, следовательно ее частота - наибольшая.
3) Медиана – значение варианты, делящей вариационный ряд пополам: по обе стороны от нее находится равное число вариант. Медиана также, как и средняя арифметическая и мода, относится к средним величинам. Обозначается как Me
4) Среднее квадратическое отклонение (синонимы: стандартное отклонение, сигмальное отклонение, сигма) - мера вариабельности вариационного ряда. Является интегральным показателем, объединяющим все случаи отклонения вариант от средней. Фактически, отвечает на вопрос: насколько далеко и как часто варианты распространяются от средней арифметической. Обозначается греческой буквой σ ("сигма") .
При численности совокупности более 30 единиц, стандартное отклонение рассчитывается по следующей формуле:
Для малых совокупностей - 30 единиц наблюдения и менее - стандартное отклонение рассчитывается по другой формуле:
Практическое занятие 1
ВАРИАЦИОННЫЕ РЯДЫ РАСПРЕДЕЛЕНИЯ
Вариационным рядом или рядом распределения называют упорядоченное распределение единиц совокупности по возрастающим (чаще) или по убывающим (реже) значениям признака и подсчет числа единиц с тем или иным значением признака.
Существует 3 вида ряда распределения:
1) ранжированный ряд – это перечень отдельных единиц совокупности в порядке возрастания изучаемого признака; если численность единиц совокупности достаточно велика ранжированный ряд становится громоздким, и в таких случаях ряд распределения строится с помощью группировки единиц совокупности по значениям изучаемого признака (если признак принимает небольшое число значений, то строится дискретный ряд, а в противном случае – интервальный ряд);
2) дискретный ряд – это таблица, состоящая из двух столбцов (строк) – конкретных значений варьирующего признака X i и числа единиц совокупности с данным значением признака f i – частот; число групп в дискретном ряду определяется числом реально существующих значений варьирующего признака;
3) интервальный ряд – это таблица, состоящая из двух столбцов (строк) – интервалов варьирующего признака X i и числа единиц совокупности, попадающих в данный интервал (частот), или долей этого числа в общей численности совокупностей (частостей).
Числа, показывающие, сколько раз отдельные варианты встречаются в данной совокупности, называются частотами или весами вариант и обозначаются строчной буквой латинского алфавита f . Общая сумма частот вариационного ряда равна объему данной совокупности, т. е.
где k – число групп, n – общее число наблюдений, или объем совокупности.
Частоты (веса) выражают не только абсолютными, но и относительными числами – в долях единицы или в процентах от общей численности вариант, составляющих данную совокупность. В таких случаях веса называют относительными частотами или частостями. Общая сумма частностей равна единице
 или
или
 ,
,
если частоты выражены в процентах от общего числа наблюдений п. Замена частот частостями не обязательна, но иногда оказывается полезной и даже необходимой в тех случаях, когда приходится сопоставлять друг с другом вариационные ряды, сильно отличающиеся по их объемам.
В зависимости от того, как варьирует признак – дискретно или непрерывно, в широком или узком диапазоне, – статистическая совокупность распределяется в безынтервальный или интервальный вариационные ряды. В первом случае частоты относятся непосредственно к ранжированным значениям признака, которые приобретают положение отдельных групп или классов вариационного ряда, во втором – подсчитывают частоты, относящиеся к отдельным промежуткам или интервалам (от – до), на которые разбивается общая вариация признака в пределах от минимальной до максимальной варианты данной совокупности. Эти промежутки, или классовые интервалы, могут быть равными и не равными по ширине. Отсюда различают равно- и неравноинтервальные вариационные ряды. В неравноинтервальных рядах характер распределения частот меняется по мере изменения ширины классовых интервалов. Неравноинтервальную группировку в биологии применяют сравнительно редко. Как правило, биометрические данные распределяются в равноинтервальные ряды, что позволяет не только выявлять закономерность варьирования, но и облегчает вычисление сводных числовых характеристик вариационного ряда, сопоставление рядов распределения друг с другом.
Приступая к построению равноинтервального вариационного ряда, важно правильно наметить ширину классового интервала. Дело в том, что грубая группировка (когда устанавливают очень широкие классовые интервалы) искажает типичные черты варьирования и ведет к снижению точности числовых характеристик ряда. При выборе чрезмерно узких интервалов точность обобщающих числовых характеристик повышается, но ряд получается слишком растянутым и не дает четкой картины варьирования.
Для получения хорошо обозримого вариационного ряда и обеспечения достаточной точности вычисляемых по нему числовых характеристик следует разбить вариацию признака (в пределах от минимальной до максимальной варианты) на такое число групп или классов, которое удовлетворяло бы обоим требованиям. Эту задачу решают делением размаха варьирования признака на число групп или классов, намечаемых при построении вариационного ряда:
 ,
,
где h – величина интервала; X м a x и X min – максимальное и минимальное значения в совокупности; k – число групп.
При построении
интервального ряда распределения
необходимо выбирать оптимальное число
групп (интервалов признака) и установливать
длину (размах) интервала. Поскольку при
анализе ряда распределения сравнивают
частоты в разных интервалах, необходимо,
чтобы длина интервалов была постоянной.
Если приходится иметь дело с интервальным
рядом распределения с неравными
интервалами, то для сопоставимости
нужно частоты или частости привести к
единице интервала, полученное значение
называется плотностью
ρ
,
то есть
 .
.
Оптимальное число групп выбирается так, чтобы достаточной мере отразилось разнообразие значений признака в совокупности и в то же время закономерность распределении, его форма не искажалась случайными колебаниями частот. Если групп будет слишком мало, не проявится закономерность вариации; если групп будет чрезмерно много, случайные скачки частот исказят форму распределения.
Чаще всего число групп в ряду распределения определяют по формуле Стерждесса:

где n – численность совокупности.
Существенную помощь в анализе ряда распределения и его свойств оказывает графическое изображение. Интервальный ряд изображается столбиковой диаграммой, в которой основания столбиков, расположенные по оси абсцисс, – это интервалы значений варьирующего признака, а высоты столбиков – частоты, соответствующие масштабу по оси ординат. Диаграмма такого типа называется гистограммой.
Если имеется дискретный ряд распределения или используются середины интервалов, то графическое изображение такого ряда называется полигоном , которое получается соединением прямыми точек с координатами X i и f i .
Если по оси абсцисс откладывать значения классов, а по оси ординат – накопленные частоты с последующим соединением точек прямыми линиями, получается график, называемый кумулятой. Накопленные частоты находят последовательным суммированием, или кумуляцией частот в направлении от первого класса до конца вариационного ряда.
Пример . Имеются данные о яйценоскости 50 кур-несушек за 1 год, содержащихся на птицеферме (табл. 1.1).
Т а б л и ц а 1.1
Яйценоскость кур-несушек
|
№ курицы-несушки |
Яйценоскость, шт. |
№ курицы-несушки |
Яйценоскость, шт. |
№ курицы-несушки |
Яйценоскость, шт. |
№ курицы-несушки |
Яйценоскость, шт. |
№ курицы-несушки |
Яйценоскость, шт. |
Требуется построить интервальный ряд распределения и отобразить его графически в виде гистограммы, полигона и кумуляты.
Видно, что признак варьирует от 212 до 245 яиц, полученных от несушки за 1 год.
В нашем примере по формуле Стерждесса определим число групп:
k = 1 + 3,322lg 50 = 6,643 ≈ 7.
Рассчитаем длину (размах) интервала по формуле:
 .
.
Построим интервальный ряд с 7 группами и интервалом 5 шт. яиц (табл. 1.2). Для построения графиков в таблице рассчитаем середину интервалов и накопленную частоту.
Т а б л и ц а 1.2
Интервальный ряд распределения яйценоскости
|
Группа кур-несушек по величине яйценоскости X i |
Число кур-несушек f i |
Середина интервала Х i ’ |
Накопленная частота f i ’ |
|
Построим гистограмму распределения яйценоскости (рис. 1.1).

Р и с. 1.1. Гистограмма распределения яйценоскости
Данные гистограммы показывают характерную для многих признаков форму распределения: чаще встречаются значения средних интервалов признака, реже – крайние (малые и большие) значения признака. Форма этого распределения близка к нормальному закону распределения, которое образуется, если на варьирующую переменную влияет большое число факторов, ни один из которых не имеет преобладающего значения.
Полигон и кумулята распределения яйценоскости имеют вид (рис. 1.2 и 1.3).

Р и с. 1.2. Полигон распределения яйценоскости

Р и с. 1.3. Кумулята распределения яйценоскости
Технология решения задачи в табличном процессоре Microsoft Excel следующая.
1. Введите исходные данные в соответствии с рис. 1.4.

2. Ранжируйте ряд.
2.1. Выделите ячейки А2:А51.
2.2. Щелкните левой кнопкой мыши на панели инструментов на кнопке <Сортировка по возрастанию > .
3. Определите величину интервала для построения интервального ряд распределения.
3.1. Скопируйте ячейку А2 в ячейку Е53.
3.2. Скопируйте ячейку А51 в ячейку Е54.
3.3. Рассчитайте размах вариации. Для этого введите в ячейку Е55 формулу =E54-E53 .
3.4. Рассчитайте число групп вариации. Для этого введите в ячейку Е56 формулу =1+3,322*LOG10(50) .
3.5. Введите в ячейку Е57 округленное число групп.
3.6. Рассчитайте длину интервала. Для этого введите в ячейку Е58 формулу =E55/E57 .
3.7. Введите в ячейку Е59 округленную длину интервала.
4. Постройте интервальный ряд.
4.1. Скопируйте ячейку Е53 в ячейку В64.
4.2. Введите в ячейку В65 формулу =B64+$E$59 .
4.3. Скопируйте ячейку В65 в ячейки В66:В70.
4.4. Введите в ячейку С64 формулу =B65 .
4.5. Введите в ячейку С65 формулу =C64+$E$59 .
4.6. Скопируйте ячейку С65 в ячейки С66:С70.
Результаты решения выводятся на экран дисплея в следующем виде (рис. 1.5).

5. Рассчитайте частоту интервалов.
5.1. Выполните команду Сервис , Анализ данных , щелкнув поочередно левой кнопкой мыши.
5.2. В диалоговом окне Анализ данных с помощью левой кнопки мыши установите: Инструменты анализа <Гистограмма> (рис. 1.6).

5.3. Щелкните левой кнопкой мыши на кнопке <ОК>.
5.4. На вкладке Гистограмма установите параметры в соответствии с рис. 1.7.

5.5. Щелкните левой кнопкой мыши на кнопке <ОК>.
Результаты решения выводятся на экран дисплея в следующем виде (рис. 1.8).

6. Заполните таблицу «Интервальный ряд распределения».
6.1. Скопируйте ячейки В74:В80 в ячейки D64:D70.
6.2. Рассчитайте сумму частот. Для этого выделите ячейки D64:D70 и щелкните левой кнопкой мыши на панели инструментов на кнопке <Автосумма > .
6.3. Рассчитайте середину интервалов. Для этого введете в ячейку Е64 формулу =(B64+C64)/2 и скопируйте в ячейки Е65:Е70.
6.4. Рассчитайте накопленные частоты. Для этого скопируйте ячейку D64 в ячейку F64. В ячейку F65 введите формулу =F64+D65 и скопируйте в ячейки F66:F70.
Результаты решения выводятся на экран дисплея в следующем виде (рис. 1.9).

7. Отредактируйте гистограмму.
7.1. Щелкните правой кнопкой мыши на диаграмме на названии «карман» и на появившейся вкладке нажмите кнопку <Очистить>.
7.2. Щелкните правой кнопкой мыши на диаграмме и на появившейся вкладке нажмите кнопку <Исходные данные>.
7.3. В диалоговом окне Исходные данные измените подписи оси Х. Для этого выделите ячейки В64:С70 (рис. 1.10).

7.5.
Нажмите
клавишу
Результаты выводятся на экран дисплея в следующем виде (рис. 1.11).

8. Постройте полигон распределения яйценоскости.
8.1. Щелкните левой кнопкой мыши на панели инструментов на кнопке <Мастер диаграмм > .
8.2. В диалоговом окне Мастер диаграмм (шаг 1 из 4) с помощью левой кнопки мыши установите: Стандартные <График> (рис. 1.12).

8.3. Щелкните левой кнопкой мыши на кнопке <Далее>.
8.4. В диалоговом окне Мастер диаграмм (шаг 2 из 4) установите параметры в соответствии с рис. 1.13.

8.5. Щелкните левой кнопкой мыши на кнопке <Далее>.
8.6. В диалоговом окне Мастер диаграмм (шаг 3 из 4) введите названия диаграммы и ос Y (рис. 1.14).

8.7. Щелкните левой кнопкой мыши на кнопке <Далее>.
8.8. В диалоговом окне Мастер диаграмм (шаг 4 из 4) установите параметры в соответствии с рис. 1.15.

8.9. Щелкните левой кнопкой мыши на кнопке <Готово>.
Результаты выводятся на экран дисплея в следующем виде (рис. 1.16).

9. Вставьте на графике подписи данных.
9.1. Щелкните правой кнопкой мыши на диаграмме и на появившейся вкладке нажмите кнопку <Исходные данные>.
9.2. В диалоговом окне Исходные данные измените подписи оси Х. Для этого выделите ячейки Е64:Е70 (рис. 1.17).

9.3.
Нажмите
клавишу
Результаты выводятся на экран дисплея в следующем виде (рис. 1.18).

Кумулята распределения строится аналогично полигону распределения на основе накопленных частот.
Совокупность значений изученного в данном эксперименте или наблюдении параметра, проранжированных по величине (возрастания или убывания) называется вариационным рядом.
Предположим, что мы измерили артериальное давление у десяти пациентов с целью получить верхний порог АД: систолическое давление, т.е. только одно число.
Представим, что серия наблюдений (статистическая совокупность) артериального систолического давления в 10-ти наблюдениях имеет следующий вид (табл. 1):
Таблица 1
Составляющие вариационного ряда называются вариантами. Варианты представляют собой числовое значение изучаемого признака.
Построение из статистической совокупности наблюдений вариационного ряда - только первый шаг к осмыслению особенностей всей совокупности. Далее необходимо определить средний уровень изучаемого количественного признака (средний уровень белка крови, средний вес пациентов, среднее время наступления наркоза и т.д.)
Средний уровень измеряют с помощью критериев, которые носят название средних величин. Средняя величина - обобщающая числовая характеристика качественно однородных величин, характеризующая одним числом всю статистическую совокупность по одному признаку. Средняя величина выражает то общее, что характерно для признака в данной совокупности наблюдений.
Общеупотребительными являются три вида средних величин: мода (), медиана () и среднеарифметическая величина ().
Для определения любой средней величины необходимо использовать результаты индивидуальных наблюдений, записав их в виде вариационного ряда (табл. 2).
Мода - значение, наиболее часто встречающееся в серии наблюдений. В нашем примере мода = 120. Если в вариационном ряду нет повторяющихся значений, то говорят, что мода отсутствует. Если несколько значений повторяются одинаковое количество раз, то в качестве моды берут наименьшее из них.
Медиана - значение, делящее распределение на две равные части, центральное или срединное значение серии наблюдений, упорядоченных по возрастанию или убыванию. Так, если в вариационном ряду 5 значений, то его медиана равна третьему члену вариационного ряда, если в ряду четное количество членов, то медиана представляет собой среднее арифметическое двух его центральных наблюдений, т.е. если в ряду 10 наблюдений, то медиана равна среднему арифметическому 5 и 6 наблюдения. В нашем примере.
Заметим важную особенность моды и медианы: на их величины не оказывают влияние числовые значения крайних вариант.
Средняя арифметическая величина рассчитывается по формуле:
где - наблюденная величина в -том наблюдении, а - число наблюдений. Для нашего случая.
Средняя арифметическая величина обладает тремя свойствами:
Средняя занимает серединное положение в вариационном ряду. В строго симметричном ряду.
Средняя является обобщающей величиной и за средней не видны случайные колебания, различия в индивидуальных данных. Она отражает то типичное, что характерно для всей совокупности.
Сумма отклонений всех вариант от средней равна нулю: . Отклонение вариант от средней обозначается.
Вариационный ряд состоит из вариант и соответствующих им частот. Из десяти полученных значений цифра 120 встретилась 6 раз, 115 - 3 раза, 125 - 1 раз. Частота () - абсолютная численность отдельных вариант в совокупности, указывающая, сколько раз встречается данная варианта в вариационном ряду.
Вариационный ряд может быть простым (частоты = 1) или сгруппированным укороченным, по 3-5 вариант. Простой ряд используется при малом числе наблюдений (), сгруппированный - при большом числе наблюдений ().
Вариационный ряд - это статистический ряд, показывающий распределение изучаемого явления по величине какого-либо количественного признака. Например, больных по возрасту, по срокам лечения, новорожденных по весу и т.п.
Варианта - отдельные значения признака, по которому проводится группировка (обозначается V ) .
Частота- число, показывающее, как часто встречается та или иная варианта (обозначается P ) . Сумма всех частот показывает общее число наблюдений и обозначается n . Разность между наибольшей и наименьшей вариантой вариационного ряда называется размахом или амплитудой .
Различают вариационные ряды:
1. Прерывные (дискретные) и непрерывные.
Ряд считается непрерывным, если группировочный признак может выражаться дробными величинами (вес, рост т.п.), прерывным, если группировочный признак выражается только целым числом (дни нетрудоспособности, число ударов пульса и т.п.).
2.Простые и взвешенные.
Простой вариационный ряд представляет собой ряд, в котором количественное значение варьирующего признака встречается один раз. Во взвешенном вариационном ряду количественные значения варьирующего признака повторяются с определённой частотой.
3. Сгруппированные (интервальные) и несгруппированые.
Сгруппированный ряд имеет варианты, объединённые в группы, объединяющие их по величине в пределах определённого интервала. В несгруппированном ряду каждой отдельной варианте соответствует определённая частота.
4. Четные и нечетные.
В чётных вариационных рядах сумма частот или общее число наблюдений выражено чётным числом, в нечётных ― нечётным.
5. Симметричные и асимметричные.
В симметричном вариационном ряду все виды средних величин совпадают или очень близки (мода, медиана, среднее арифметическое).
В зависимости от характера изучаемых явлений, от конкретных задач и целей статистического исследования, а также от содержания исходного материала, в санитарной статистике применяются следующие виды средних величин:
структурные средние (мода, медиана);
средняя арифметическая;
средняя гармоническая;
средняя геометрическая;
средняя прогрессивная.
Мода (М о ) - величина варьирующего признака, которая более часто встречается в изучаемой совокупности т.е. варианта, соответствующая наибольшей частоте. Находят ее непосредственно по структуре вариационного ряда, не прибегая к каким-либо вычислениям. Она обычно является величиной очень близкой к средней арифметической и весьма удобна в практической деятельности.
Медиана (М е ) - делящая вариационный ряд (ранжированный, т.е. значения вариант располагаются в порядке возрастания или убывания) на две равные половины. Медиана вычисляется при помощи так называемого нечетного ряда, который получают путем последовательного суммирования частот. Если сумма частот соответствует четному числу, тогда за медиану условно принимают среднюю арифметическую из двух средних значений.
Мода и медиана применяются в случае незамкнутой совокупности, т.е. когда наибольшая или наименьшая варианты не имеют точной количественной характеристики (например, до 15 лет, 50 и старше и т.п.). В этом случае среднюю арифметическую (параметрические характеристики) рассчитать нельзя.
Средня я арифметическая - самая распространенная величина. Средняя арифметическая обозначается чаще через М .
Различают среднюю арифметическую простую и взвешенную.
Средняя арифметическая простая вычисляется:
― в тех случаях, когда совокупность представлена простым перечнем знаний признака у каждой единицы;
― если число повторений каждой варианты нет возможности определить;
― если числа повторений каждой варианты близки между собой.
Средняя арифметическая простая исчисляется по формуле:
где V - индивидуальные
значения признака; n
- число индивидуальных значений;  - знак суммирования.
- знак суммирования.
Таким образом, простая средняя представляет собой отношение суммы вариант к числу наблюдений.
Пример: определить среднюю длительность пребывания на койке 10 больных пневмонией:
16 дней - 1 больной; 17–1; 18–1; 19–1; 20–1; 21–1; 22–1; 23–1; 26–1; 31–1.
койко-дня.
Средняя арифметическая взвешенная исчисляется в тех случаях, когда индивидуальные значения признака повторяются. Ее можно вычислять двояким способом:
1. Непосредственным (среднеарифметическим или прямым способом) по формуле:
 ,
,
где P - частота (число случаев) наблюдений каждой варианты.
Таким образом, средняя арифметическая взвешенная представляет собой отношение суммы произведений вариант на частоты к числу наблюдений.
2. С помощью вычисления отклонений от условной средней (по способу моментов).
Основой для вычисления взвешенной средней арифметической является:
― сгруппированный материал по вариантам количественного признака;
― все варианты должны располагаться в порядке возрастания или убывания величины признака (ранжированный ряд).
Для вычисления по способу моментов обязательным условием является одинаковый размер всех интервалов.
По способу моментов средняя арифметическая вычисляется по формуле:
 ,
,
где М о - условная средняя, за которую чаще принимают величину признака, соответствующую наибольшей частоте, т.е. которая чаще повторяется (Мода).
i - величина интервала.
a - условное отклонение от условий средней, представляющее собой последовательный ряд чисел (1, 2 и т.д.) со знаком + для вариант больших условной средней и со знаком–(–1, –2 и т.д.) для вариант, которые ниже условной средней. Условное же отклонение от варианты, принятой за условную среднюю равно 0.
P - частоты.
 - общее число наблюдений или n.
- общее число наблюдений или n.
Пример: определить средний рост мальчиков 8 лет непосредственным способом (таблица1).
Т а б л и ц а 1
|
Рост в см |
мальчиков P |
Центральная варианта V | |
Центральная варианта ― середина интервала ― определяется как полу сумма начальных значений двух соседних групп:
 ;
;  и т.д.
и т.д.
Произведение VP
получают путем умножения центральных
вариант на частоты
 ;
; и т.д. Затем полученные произведения
складывают и получают
и т.д. Затем полученные произведения
складывают и получают ,
которую делят на число наблюдений (100)
и получают среднюю арифметическую
взвешенную.
,
которую делят на число наблюдений (100)
и получают среднюю арифметическую
взвешенную.
 см.
см.
Эту же задачу решим по способу моментов, для чего составляется следующая таблица 2:
Т а б л и ц а 2
|
Рост в см (V) |
мальчиков P | ||
n=100 
В
качестве М о
принимаем 122, т.к. из 100 наблюдений у 33
человек рост был 122см. Находим условные
отклонения (a) от условной средней в
соответствии с вышесказанным. Затем
получаем произведение условных отклонений
на частоты (aP) и суммируем полученные
величины ( ).
В итоге получится 17. Наконец, данные
подставляем в формулу:
).
В итоге получится 17. Наконец, данные
подставляем в формулу:

При изучении варьирующего признака нельзя ограничиваться только вычислением средних величин. Необходимо вычислять и показатели, характеризующие степень разнообразия изучаемых признаков. Величина того или иного количественного признака неодинакова у всех единиц статистической совокупности.
Характеристикой
вариационного ряда является среднее
квадратичное отклонение ( ),
которое показывает разброс (рассеивание)
изучаемых признаков относительно
средней арифметической, т.е. характеризует
колеблемость вариационного ряда. Оно
может определяться непосредственным
способом по формуле:
),
которое показывает разброс (рассеивание)
изучаемых признаков относительно
средней арифметической, т.е. характеризует
колеблемость вариационного ряда. Оно
может определяться непосредственным
способом по формуле:

Среднее квадратичное
отклонение равняется квадратному корню
из суммы
произведений квадратов отклонений
каждой варианты от средней арифметической
(V–M) 2
на свои частоты деленной на сумму частот
( ).
).
Пример вычисления: определить среднее число больничных листов, выдаваемых в поликлинике за день (таблица 3).
Т а б л и ц а 3
|
Число больничных листов, выданных врачом за день (V) |
Число врачей (Р) | ||||
 ;
; 
В знаменателе при
числе наблюдений менее 30 необходимо от
 отнимать единицу.
отнимать единицу.
Если ряд сгруппирован с равными интервалами, тогда можно определить среднее квадратичное отклонение по способу моментов:
 ,
,
где i - величина интервала;
 - условное отклонение от условной
средней;
- условное отклонение от условной
средней;
P - частоты вариант соответствующих интервалов;
 - общее число наблюдений.
- общее число наблюдений.
Пример вычисления : Определить среднюю длительность пребывания больных на терапевтической койке (по способу моментов) (таблица 4):
Т а б л и ц а 4
|
Число дней пребывания на койке (V) |
больных (Р) |
|
|
|



 ;
;
Бельгийский
статистик А. Кетле обнаружил, что вариации
массовых явлений подчиняются закону
распределения ошибок, открытому почти
одновременно К. Гауссом и П. Лапласом.
Кривая, отображающая это распределение,
имеет вид колокола. По нормальному
закону распределения колеблемость
индивидуальных значений признака
находится в пределах
 ,
что охватывает 99,73% всех единиц
совокупности.
,
что охватывает 99,73% всех единиц
совокупности.
Подсчитано, что
если к средней арифметической прибавить
и отнять 2 ,
то в пределах полученных величин
находится 95,45% всех членов вариационного
ряда и, наконец, если к средней
арифметической прибавить и отнять 1
,
то в пределах полученных величин
находится 95,45% всех членов вариационного
ряда и, наконец, если к средней
арифметической прибавить и отнять 1 ,
то в пределах полученных величин будут
находиться 68,27% всех членов данного
вариационного ряда. В медицине с величиной
,
то в пределах полученных величин будут
находиться 68,27% всех членов данного
вариационного ряда. В медицине с величиной 1
1 связано понятие нормы. Отклонение от
средней арифметической больше, чем на
1
связано понятие нормы. Отклонение от
средней арифметической больше, чем на
1 ,
но меньше, чем на 2
,
но меньше, чем на 2 является субнормальным, а отклонение
больше, чем на 2
является субнормальным, а отклонение
больше, чем на 2 ненормальным (выше или ниже нормы).
ненормальным (выше или ниже нормы).
В санитарной статистике правило трех сигм применяется при изучении физического развития, оценке деятельности учреждений здравоохранения, оценке здоровья населения. Это же правило широко применяется в народном хозяйстве при определении стандартов.
Таким образом, среднее квадратичное отклонение служит для:
― измерения дисперсии вариационного ряда;
― характеристики степени разнообразия признаков, которые определяются коэффициентом вариации:

Если коэффициент вариации более 20% - сильное разнообразие, от 20 до 10% - среднее, менее 10% - слабое разнообразие признаков. Коэффициент вариации в известной мере является критерием надежности средней арифметической.