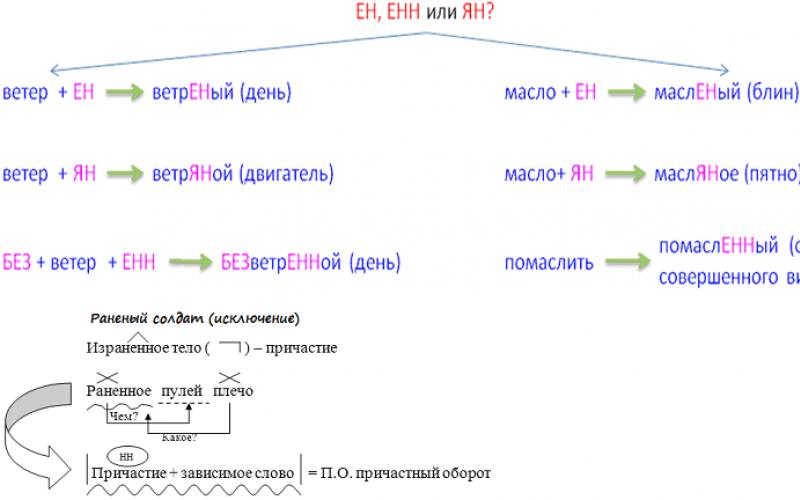
Означающее неоднородность наблюдений, выражающуюся в неодинаковой (непостоянной) дисперсии случайной ошибки регрессионной (эконометрической) модели. Гетероскедастичность противоположна понятию гомоскедастичность , которое означает однородность наблюдений, то есть постоянство дисперсии случайных ошибок модели.
Наличие гетероскедастичности случайных ошибок приводит к неэффективности оценок , полученных с помощью метода наименьших квадратов . Кроме того, в этом случае оказывается смещённой и несостоятельной классическая оценка ковариационной матрицы МНК-оценок параметров. Следовательно статистические выводы о качестве полученных оценок могут быть неадекватными. В связи с этим тестирование моделей на гетероскедастичность является одной из необходимых процедур при построении регрессионных моделей.
Тестирование гетероскедастичности
В первом приближении наличие гетероскедастичности можно заметить на графиках остатков регрессии (или их квадратов) по некоторым переменным, по оцененной зависимой переменной или по номеру наблюдения. На этих графиках разброс точек может меняться в зависимости от значения этих переменных.
Для более строгой проверки применяют, например, следующие статистические тесты
- Тест Голдфелда-Куандта
- Тест Бройша - Пагана
- Тест Парка
- Тест Глейзера
- Тест ранговой корреляции Спирмэна
Оценка модели при гетероскедастичности
Поскольку МНК-оценки параметров моделей остаются несмещёнными состоятельными даже при гетероскедастичности, то при достаточном количестве наблюдений возможно применение обычного МНК. Однако, для более точных и правильных статистических выводов необходимо использовать стандартные ошибки в форме Уайта .
Альтернативный подход - использование взвешенного метода наименьших квадратов (ВМНК, WLS) . В этом методе каждое наблюдение взвешивается обратно пропорционально предполагаемому стандартному отклонению случайной ошибки в этом наблюдении. Такой подход позволяет сделать случайные ошибки модели гомоскедастичными.
В частности, если предполагается, что стандартное отклонение ошибок пропорционально некоторой переменной Z , то данные делятся на эту переменную, включая константу.
Пример
Пусть рассматривается, например, зависимость прибыли от размера активов:
Однако, скорее всего не только прибыль зависит от активов, но и "колеблемость" прибыли не одинакова для той или иной величины активов. То есть скорее всего стандартное отклонение случайной ошибки модели следует полагать пропорциональным стоимости активов:
В этом случае разумнее рассматривать не исходную модель, а следующую:
предполагая что в этой модели случайные ошибки гомоскедастичны. Можно использовать эту преобразованную модель непосредственно, а можно использовать полученные оценки параметров как оценки параметров исходной модели (взвешенный МНК). Теоретически полученные таким образом оценки должны быть лучше.
См. также
Литература
- Магнус Я. Р., Катышев П. К., Пересецкий А. А. Эконометрика. - М .: Дело, 2004. - 576 с.
- William H. Greene Econometric analysis. - New York: Pearson Education, Inc., 2003. - 1026 с.
Wikimedia Foundation . 2010 .
Смотреть что такое "Гетероскедастичность" в других словарях:
- (heteroscedasticity) Разнородность; наличие различных дисперсий. Данные являются гетероскедастическими, если их вариации не соответствуют случайным отклонениям по той же совокупности. Это понятие отличается от гомоскедастичности… … Экономический словарь
Гетероскедастичность - , неоднородность понятие математической статистики и эконометрии; означает случай, когда дисперсия ошибки в уравнении регрессии изменяется от наблюдения к наблюдению. В этом случае приходится подвергать определенной… … Экономико-математический словарь
гетероскедастичность - Неоднородность понятие математической статистики и эконометрии; означает случай, когда дисперсия ошибки в уравнении регрессии изменяется от наблюдения к наблюдению. В этом случае приходится подвергать определенной модификации метод наименьших… … Справочник технического переводчика
гетероскедастичность - Неоднородность дисперсии. Антоним: гомоскедастичность … Словарь социологической статистики
- (ARCH AutoRegressive Conditional Heteroskedastiсity) применяемая в эконометрике модель для анализа временных рядов (в первую очередь финансовых) у которых условная (по прошлым значениям ряда) дисперсия ряда зависит от прошлых значений … Википедия
Куандта (англ. Goldfeld Quandt test) процедура тестирования гетероскедастичности случайных ошибок регрессионной модели, применяемая в случае, когда есть основания полагать, что стандартное отклонение ошибок может быть пропорционально… … Википедия
- (англ. White test) универсальная процедура тестирования гетероскедастичности случайных ошибок линейной регрессионной модели, не налагающая особых ограничений на структуру гетероскедастичности, предложенная Уайтом в 1980 г. Тест является… … Википедия
При проведении регрессионного анализа методом наименьших квадратов (МНК) важно учитывать предпосылки этого метода, одной из которых является равенство дисперсий случайных отклонений. Выполнение данной предпосылки называется гомоскедастичностью,… … Википедия
Применяемая в эконометрике модель для отыскания зависимости дисперсии текущей ошибки от квадратов ошибок модели для предшествующих наблюдений. Спецификация ARCH(q) Обозначим через текущую ошибку модели и предположим, что, где и где временной ряд … Википедия
- (ОМНК, GLS англ. Generalized Least Squares) метод оценки параметров регрессионных моделей, являющийся обобщением классического метода наименьших квадратов. Обобщённый метод наименьших квадратов сводится к минимизации «обобщённой… … Википедия
Книги
- Введение в эконометрику (CDpc) , Яновский Леонид Петрович, Буховец Алексей Георгиевич. Даны основы эконометрики и статистического анализа одномерных временных рядов. Большое внимание уделено классической парной и множественной регрессии, классическому и обобщенному методам…
Проверить наличие гетероскедастичности в модели. Объяснить полученные результаты.
Если остатки имеют постоянную дисперсию, они называются гомоскедастичными , но если они непостоянны, то гетероскедастичными . Гетероскедастичность приводит к тому, что коэффициенты регрессии больше не представляют собой лучшие оценки или не являются оценками с минимальной дисперсией, следовательно, они больше не являются наиболее эффективными коэффициентами.
Воздействие гетероскедастичности на оценку интервала прогнозирования и проверку гипотезы заключается в том, что хотя коэффициенты не смещены, дисперсии и, следовательно, стандартные ошибки этих коэффициентов будут смещены. Если смещение отрицательно, то оценочные стандартные ошибки будут меньше, чем они должны быть, а критерий проверки будет больше, чем в реальности. Таким образом, мы можем сделать вывод, что коэффициент значим, когда он таковым не является. И наоборот, если смещение положительно, то оценочные ошибки будут больше, чем они должны быть, а критерии проверки – меньше. Значит, мы можем принять нулевую гипотезу, в то время как она должна быть отвергнута.
Проверкой на гетероскедастичность служит тест Голдфелда-Кванта. Он требует, чтобы остатки были разделены на две группы из наблюдений, одна группа с низкими, а другая – с высокими значениями. Обычно срединная одна шестая часть наблюдений удаляется после ранжирования в возрастающем порядке, чтобы улучшить разграничение между двумя группами. Отсюда число остатков в каждой группе составляет , где представляет одну шестую часть наблюдений.
Критерий Голдфелда-Кванта – это отношение суммы квадратов отклонений (СКО) высоких остатков к СКО низких остатков:
Этот критерий имеет распределение с ![]() степенями свободы.
степенями свободы.
Чтобы решить проблему гетероскедастичности, нужно исследовать взаимосвязь между значениями ошибки и переменными и трансформировать регрессионную модель так, чтобы она отражала эту взаимосвязь. Это может быть достигнуто посредством регрессии значений ошибок по различным формам функций переменной, которая приводит к гетероскедастичности, например,
![]() ,
,
где - независимая переменная (или какая-либо функция независимой переменной), которая предположительно является причиной гетероскедастичности, а отражает степень взаимосвязи между ошибками и данной переменной, например, или и т. д.
Следовательно, дисперсия коэффициентов запишется:
![]() .
.
Отсюда если , мы трансформируем регрессионную модель к виду:
 .
.
Если , т.е. дисперсия увеличивается в пропорции к квадрату рассматриваемой переменной , трансформация приобретает вид:
 .
.
Используя Eviews, можно провести проверку и устранение гетероскедастичности следующим образом:
Ø Запустить стандартную регрессию.
Ø Вычислить остатки.
Ø Запустить регрессию с использованием квадрата остатков как зависимой переменной и оценить зависимую переменную как независимую переменную (тест White).
Ø Оценить nR 2 , где n – объем выборки, R 2 – коэффициент детерминации.
Ø Использовать статистику с одной степенью свободы (в EVIEWS – используется F – статистика) для проверки существенности отличия nR 2 от нуля.
Ø Основным способом устранения гетероскедастичности является применение взвешенного метода наименьших квадратов.
Выбираем тест White (см. рис. 64).

Итог формы вывода представлен на рис. 65.

Обнаружение гетероскедастичности
В случае парной регрессии о проявлении гетероскедастичности можно судить по характеру расположения экспериментальных точек на корреляционном поле (рис. 5.1). На рис. 5.1 можно заметить, что дисперсии случайных отклонений неодинаковы и увеличиваются с возрастанием значений объясняющей переменной. Однако даже для парной регрессии выводы по определению гетероскедастичности могут являться неоднозначными при наличии локальных «выбросов» точек (пиков на диаграмме рассеивания). Естественно, что для множественной регрессии обнаружение гетероскедастичности является значительно более сложной задачей, чем для моделей с одним регрессором.


В настоящее время существует достаточно большое количество тестов для поверки на гетероскедастичность, базирующихся на дисперсионном анализе случайных отклонений. Рассмотрим наиболее распространенные из них.
Тест ранговой корреляции Спирмена . Идея данного теста заключается в том, что в случае гетероскедастичности дисперсия случайного отклонения будет либо увеличиваться, либо уменьшаться с увеличением значений регрессоров Х . Поэтому для регрессионной модели, построенной по МНК, абсолютные значения оценок отклонений e i и значения x i будут коррелированны.
Значения e i и x i ранжируются (упорядочиваются по величинам). Номеру i значения x i в упорядоченном ряду будет соответствовать ранг r xi . Аналогично упорядочим данные по абсолютным значениям остатков и каждому |e i | припишем ранг r ei . Тогда разность между рангами (d i ) запишем как d i = r xi - r ei . Например, если x 20 является 25-м по величие среди всех значений X , а e 20 является 30-м, то d i = 25 - 30 = -5.
Коэффициент ранговой корреляции Спирмена вычисляется по формуле
 (5.2)
(5.2)
где n - число наблюдений.
Доказано, что при n > 10 статистика
 (5.3)
(5.3)
имеет t -распределение Стьюдента с числом степеней свободы v = n - 2.
Следовательно, в соответствии со схемой проверки статистических гипотез, если наблюдаемое значение t -статистики, рассчитанное по формуле (5.3), превышает t кр = t a , n - 2 (табличное), то необходимо отклонить гипотезу Н 0 об отсутствии гетероскедастичности. В противном случае гипотеза Н 0 принимается, что соответствует гомоскедастичности.
Если анализируется модель множественной регрессии, то проверка гипотезы осуществляется с помощью t -статистики для каждой объясняющей переменной отдельно.
Следует заметить, что коэффициент ранговой корреляции Спирмена (r ) может иметь самостоятельное значение в эконометрических исследованиях. Он используется при установлении тесноты связи между порядковыми переменными. В этом случае анализируемые объекты упорядочивают по степени влияния (проявления) признака. Если объекты ранжированы по двум признакам Х иY , то имеется возможность оценить тесноту связи между этими переменными, основываясь на рангах. В том случае, если ранги всех объектов равны, то r = 1 (полная прямая связь). При полной обратной связи ранги объектов по двум переменным расположены в обратном порядке и r = -1. Во всех остальных случаях |r | < 1. Применение коэффициента ранговой корреляции не требует нормального распределения переменных и линейной связи между ними. Однако необходимо учитывать, что в случае количественных переменных переход от их первоначальных значений и размерностей к рангам сопровождается определенной потерей информации.
Тест Голдфелда-Квандта. Этот тест использует предположения о нормальности распределения случайных отклонений и о пропорциональности средних квадратических (стандартных) отклонений σ i = σ(e i ) значениям соответствующей объясняющей переменной X .
В рамках этих предположений Голдфелд и Квандт предложили следующую процедуру проверки на гетероскедастичность:
1. Все n наблюдений упорядочиваются в порядке возрастания значений регрессора X , и выборка после этого разбивается на три подвыборки размерностей k , n - 2k , k соответственно.
2. Оцениваются отдельные регрессии для первой и третьей подвыборок (рассматриваем k первых значений и k последних; средние n - 2k наблюдений отбрасываем).
3. Если, в соответствии с нашим предположением, дисперсия случайных отклонений увеличивается с ростом X
, то дисперсия регрессии по первой подвыборке (сумма квадратов остатков ) будет существенно меньше дисперсии регрессии по третьей подвыборке (суммы квадратов остатков  ).
).
4. Для сравнения соответствующих дисперсий определяется следующая F -статистика:
 . (5.4)
. (5.4)
Здесь (k - m - 1) – числа степеней свободы соответствующих выборочных дисперсий (m - одинаковое количество объясняющих переменных в уравнениях регрессии). При выполнении начальных предположений относительно остатков построенная F -статистика имеет распределение Фишера с числами степеней свободы v 1 = v 2 = k - m - 1.
5. Если наблюдаемое значение F
-статистики (F набл
), рассчитанное по формуле (5.4), превосходит ее критическое значение ![]() , то гипотеза об отсутствии гетероскедастичности (о равенстве дисперсий) отклоняется на выбранном уровне значимости a.
, то гипотеза об отсутствии гетероскедастичности (о равенстве дисперсий) отклоняется на выбранном уровне значимости a.
Мощность теста Голдфелда-Квандта, т. е. вероятность отвергнуть гипотезу об отсутствии гетероскедастичности в случае, когда ее действительно нет, оказывается максимальной, если выбирать k » n /3.
Для множественной регрессии данный тест может осуществляться для каждой из объясняющих переменных или для одного выбранного регрессора, который в наибольшей степени связан с σ i .
Аналогичный тест может быть использован при условии обратной пропорциональности между стандартными отклонениями остатков σ i и значениями объясняющей переменной. При этом статистика Фишера примет вид: F = S 1 /S 3 .
Тест Уайта. Сущность данного теста заключается в том, что если в модели присутствует гетероскедастичность, то дисперсии случайных отклонений некоторым образом зависят от регрессоров; т. е. гетероскедастичность должна как-то проявляться в поведении остатков исходной регрессионной модели. Исходя из этого при использовании теста Уайта предполагается, что дисперсии остатков представляют собой некоторую функцию от наблюдаемых значений объясняющих переменных
Для получения соответствующих выводов осуществляется оценка функции (5.5) с помощью уравнения регрессии для квадратов остатков:
где v i - случайный член.
На практике чаще всего функция f выбирается квадратичной, а регрессоры в уравнении (5.6) – это регрессоры исходной модели, их квадраты и, возможно, попарные произведения. Для данного теста гипотеза об отсутствии гетероскедастичности, что соответствует условию f = const , принимается в случае незначимости регрессии (5.6) в целом.
Следует заметить, что во всех рассматриваемых тестах (критериях) осуществляется проверка нулевой гипотезы Н 0 об отсутствии гетероскедастичности.
Гетероскедастичность
Случайной ошибкой называется отклонение в линейной модели множественной регрессии:
εi=yi–β0–β1x1i–…–βmxmi
В связи с тем, что величина случайной ошибки модели регрессии является неизвестной величиной, рассчитывается выборочная оценка случайной ошибки модели регрессии по формуле:
где ei – остатки модели регрессии.
Термин гетероскедастичность в широком смысле понимается как предположение о дисперсии случайных ошибок модели регрессии.
При построении нормальной линейной модели регрессии учитываются следующие условия, касающиеся случайной ошибки модели регрессии:
6) математическое ожидание случайной ошибки модели регрессии равно нулю во всех наблюдениях:
![]()
7) дисперсия случайной ошибки модели регрессии постоянна для всех наблюдений:
8) между значениями случайных ошибок модели регрессии в любых двух наблюдениях отсутствует систематическая взаимосвязь, т. е. случайные ошибки модели регрессии не коррелированны между собой (ковариация случайных ошибок любых двух разных наблюдений равна нулю):
Второе условие
означает гомоскедастичность (homoscedasticity – однородный разброс) дисперсий случайных ошибок модели регрессии.
Под гомоскедастичностью понимается предположение о том, что дисперсия случайной ошибки βi является известной постоянной величиной для всех наблюдений.
Но на практике предположение о гомоскедастичности случайной ошибки βi или остатков модели регрессии ei выполняется не всегда.
Под гетероскедастичностью (heteroscedasticity – неоднородный разброс) понимается предположение о том, что дисперсии случайных ошибок являются разными величинами для всех наблюдений, что означает нарушение второго условия нормальной линейной модели множественной регрессии:
Гетероскедастичность можно записать через ковариационную матрицу случайных ошибок модели регрессии:

Тогда можно утверждать, что случайная ошибка модели регрессии βi подчиняется нормальному закону распределения с нулевым математическим ожиданием и дисперсией G2Ω:
где Ω – матрица ковариаций случайной ошибки.
Если дисперсии случайных ошибок
модели регрессии известны заранее, то проблема гетероскедастичности легко устраняется. Однако в большинстве случаев неизвестными являются не только дисперсии случайных ошибок, но и сама функция регрессионной зависимости y=f(x), которую предстоит построить и оценить.
Для обнаружения гетероскедастичности остатков модели регрессии необходимо провести их анализ. При этом проверяются следующие гипотезы.
Основная гипотеза H0 предполагает постоянство дисперсий случайных ошибок модели регрессии, т. е. присутствие в модели условия гомоскедастичности:
Альтернативная гипотеза H1 предполагает непостоянство дисперсиий случайных ошибок в различных наблюдениях, т. е. присутствие в модели условия гетероскедастичности:
Гетероскедастичность остатков модели регрессии может привести к негативным последствиям:
1) оценки неизвестных коэффициентов нормальной линейной модели регрессии являются несмещёнными и состоятельными, но при этом теряется свойство эффективности;
2) существует большая вероятность того, что оценки стандартных ошибок коэффициентов модели регрессии будут рассчитаны неверно, что конечном итоге может привести к утверждению неверной гипотезы о значимости коэффициентов регрессии и значимости модели регрессии в целом.
Гомоскедастичность
Гомоскедастичность остатков означает, что дисперсия каждого отклонения одинакова для всех значений x. Если это условие не соблюдается, то имеет место гетероскедастичность. Наличие гетероскедастичности можно наглядно видеть из поля корреляции.


Т.к. дисперсия характеризует отклонение то из рисунков видно, что в первом случае дисперсия остатков растет по мере увеличения x, а во втором – дисперсия остатков достигает максимальной величины при средних значениях величины x и уменьшается при минимальных и максимальных значениях x. Наличие гетероскедастичности будет сказываться на уменьшении эффективности оценок параметров уравнения регрессии. Наличие гомоскедастичности или гетероскедастичности можно определять также по графику зависимости остатков от теоретических значений .

Предположение о постоянстве и конечности дисперсии остатков называется свойством гомоскедастичности остатков (рисунок 5.1). В практических исследованиях это свойство случайной ошибки модели регрессии не всегда выполняется и дисперсия остатков не является постоянной величиной (рисунок 5.2). Такое явление называется гетероскедастичностью .
Рис. 5.1. Линейная модель с гомоскедастичностью
Гетероскедастичность часто вызывается ошибками спецификации, когда не учитывается в модели существенная переменная.
Гетероскедастичность приводит к тому, что оценки коэффициентов регрессии не являются эффективными, т.е. их дисперсии не будут наименьшими. Как следствие рассчитанные значения стандартных ошибок коэффициентов регрессии могут быть заниженными, а потому при проверке статистической значимости коэффициентов может быть ошибочно принято решение об их значимом отличии от нуля, тогда как на самом деле это не так.
Проблема гетероскедастичности характерна для пространственных данных, полученных от неоднородных объектов. Например, если исследуется зависимость расходов на питание в семье от ее общего дохода, то можно ожидать, что разброс данных будет выше для семей с более высоким доходом. Если исследуется зависимость оплаты труда сотрудников предприятий в зависимости от размера основных фондов предприятий и разряда работника, то понятно, что вариация оплаты труда на крупных предприятиях у сотрудников высокого разряда будет значительно превосходить его вариацию для сотрудников низких уровней на малых и средних предприятиях.
Гетероскедастичность иногда возникает и во временных рядах. Это происходит в тех случаях, когда зависимая переменная имеет большой интервал качественно неоднородных значений или высокий темп изменения (инфляция, технологические сдвиги, изменения в законодательстве, потребительские предпочтения и т.д.).

Рис. 5.2. Линейная модель с гетероскедастичностью
В настоящее время для оценки нарушения гомоскедастичности предложено большое число тестов. Чаще всего используются графический анализ отклонений, тест ранговой корреляции Спирмена и тест Голдфелда-Квандта.
Графический анализ отклонений заключается в визуальной оценке разброса точек корреляционного поля около линии регрессии: считается, что условие 2 выполняется, если точки наблюдений расположены внутри полосы постоянной ширины, окаймляющей линию регрессии (например, как на рисунке 5.1). Для множественной регрессии осуществляется графический анализ корреляционных полей объясняемой переменной в зависимости от каждого из факторов .
Наиболее популярным тестом обнаружения гетероскедастичности является тест Голдфелда-Квандта. Тест применяется в том случае, если ошибки регрессии можно считать нормально распределенными случайными величинами. Кроме того, в основе его лежит предположение о пропорциональности дисперсий случайного члена значению выбранной объясняющей переменной. Тест проводится по следующей схеме.
1. На основе выборочных данных строится линейная модель множественной регрессии с объясняющими переменными .
2. В модели множественной регрессии (например, на основе графического анализа) выбирается факторная переменная, от которой предположительно могут зависеть остатки. Значения этой переменной ранжируются, располагаются по возрастанию и делятся на три части объемами (обычно принимают ).
3. Для первой и третьей частей строятся две независимые модели регрессии.
4. По каждой из построенных моделей рассчитывают суммы квадратов остатков S 1 и S 3 .
5. Осуществляется проверка основной гипотезы об отсутствии гетероскедастичности с помощью -критерия Фишера. Наблюдаемое значение -критерия рассчитывается следующим образом:
Если , то в основной модели присутствует гетероскедастичность, зависящая от выбранной объясняющей переменной (число степеней свободы определяется значениями ![]() и
и ![]() ).
).
Если нет уверенности относительно выбора объясняющей переменной, вызывающей гетероскедастичность, то тест осуществляется для каждой из объясняющих переменных .
Наличие гетероскедастичности в остатках регрессии можно проверить и с помощью теста ранговой корреляции Спирмена. При выполнении теста предполагается, что абсолютные величины остатков и значения объясняющей переменной коррелированны. Эту корреляцию можно измерять с помощью коэффициента ранговой корреляции Спирмена:
 ,
,
где – разность между рангом и рангом модуля остатка .
Тест проводится по следующей схеме.
1. Строится линейная модель регрессии.
2. Данные по и модули остатков ранжируются по переменной , определяются их ранги (ранг – это порядковый номер значений переменной в ранжированном ряду).
3. Осуществляется проверка основной гипотезы об отсутствии гетероскедастичности с помощью -статистики с степенями свободы, где n
– объем выборки. При этом наблюдаемое значение -критерия определяется равенством  . Если , то нулевая гипотеза об отсутствии гетероскедастичности отклоняется и имеет место гетероскедастичность в остатках регрессии, т.е. условие 2 не выполняется.
. Если , то нулевая гипотеза об отсутствии гетероскедастичности отклоняется и имеет место гетероскедастичность в остатках регрессии, т.е. условие 2 не выполняется.
После установления в модели наличия гетероскедастичности возникает вопрос о том, в какой мере существенно она влияет на качество модели и следует ли вообще с гетероскедастичностью бороться. Ведь при гетероскедастичности оценки коэффициентов регрессии все равно остаются несмещенными и состоятельными, правда, не будут эффективными.
Если исследователь решил вступить в борьбу с гетероскедастичностью, то первый шаг на этом пути заключается в определении ее типа. Если гетероскедастичность вызвана ошибками спецификации, то для ее устранения необходимо включить в уравнение пропущенные существенные переменные и подобрать правильную функциональную форму. Если гетероскедастичность наблюдается в правильно специфицированных моделях (чистая гетероскедастичность ), то можно воспользоваться взвешенным методом наименьших квадратов (ВМНК).
Данный метод применяется при известных для каждого наблюдения значениях дисперсиях . В этом случае можно устранить гетероскедастичность, разделив каждое наблюдаемое значение на соответствующее ему среднеквадратическое отклонение. Тем самым обеспечивается равномерный вклад остатков в общую сумму.
Таким образом, если при обычном МНК в случае парной линейной модели ![]() для нахождения ее параметров и минимизируется сумма
для нахождения ее параметров и минимизируется сумма ![]() , то при ВМНК минимизируется сумма
, то при ВМНК минимизируется сумма

 .
.
Применение ВМНК включает следующие этапы.
1. С помощью обычного МНК строится линейная регрессионная модель и
доказывается наличие гетероскедастичности остатков.
2. Для каждого наблюдения устанавливаются фактические значения дисперсий отклонений.
3. Значения каждой пары наблюдений делятся на известную величину . Тем самым наблюдениям с наименьшими дисперсиями придаются наибольшие веса, а наблюдениям с наибольшими дисперсиями – наименьшие веса.